Enterprise Lineage | Implementing Enterprise Lineage
Background
Data lineage is an important concept in information technology because it provides 'meta' information about data that enables us to see where a value came from, how it was manipulated/consolidated and what the information can reasonably used for. "Balance" for cash-accounts is different from "Balance" of all accounts (including loans & mortgages) and different from "Balance" including fungible value of assets held as security – knowing the lineage of a value determines in which context it can be used.
Aside from the constituents and usage of data, lineage enables us to build confidence in the values:
- back-testing an individual value to determine the quality of the information (an aggregate of credit and debit accounts is functional dependant on the accounting convention used), and currency values cannot be aggregated without applying an exchange rate.
- establishing that the sources of value is complete and consistent conversions are applied.
It is a common mistake to conflate internal and external data-lineage requirements as being the same thing, and treat them as the same problem. This can lead to an internal data-processing approach to a lineage, where the external requirement is only concerned with the ultimate inputs and outputs.
Internal-data-lineage is important for internal quality and testing, but in large organisation (with hundreds of process steps) it obscures the external-data-lineage, and might not meet external needs
Internal Lineage
The traditional approach to data-lineage is to map the association from each attribute source to each attribute destination using database Extract/Transform/Load (ETL); Enterprise Application Integration (EAI); or in heterogeneous environments stand-alone Data-Dictionaries (with pre-built data loaders for common ETL/EAI scenarios).
It is also possible to document these relationships in UML modelling tools (like Sparx Enterprise Architect) using attribute specific associations between classes. The diagram at the top of the page shows the ETL mapping for a data transfer. All ETL/EAI tools obscure detailed calculations, partly because of tool limitations, but mostly because complex calculations (VaR, xVA, RWA, etc ) cannot be represented as lineage graphs.
In all cases, tooling support it critical to reduce the effort of mapping, but often at great cost.
External Lineage
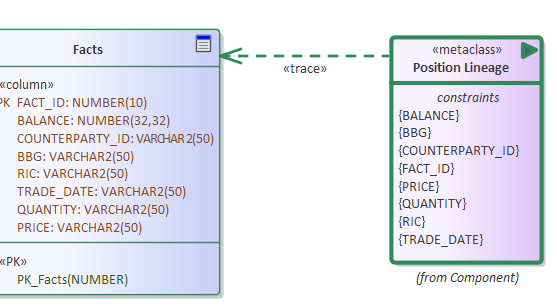

An alternative (simpler) approach is to separate the details of field-level derivation from the summary view of metadata lineage, taking advantages of the fact that in 95% of cases attributes have the same name (in finance Reuters instrument code is always RIC) and in the remaining cases an alias can be used (ETL tools always presume this to start). The detailed mapping can be replace by a single trace reference.
The advantage of using <<trace>> references is that the diagrams remain domain focused (without the clutter of detail), and changes to attributes imply changes to lineage, and updates do not need to be cascaded through a myriad of related diagrams. In UML the Lineage can be represented as <<metadata>> Information Items where constraints represents the lineage rules.
It will be demonstrated that the constraints can be automatically derived by recursively scanning all trace relationships to algorithmically summarise the lineage in real-time in an enterprise hub. In our solution, the lineage constraint is represented as JSON array graph that can be imported into visualisation tools if required. Whilst a raw JSON graph does not provide compelling presentation it does allow gap to be highlighted
["SimpleBank.Databases.WareHouse.Price.MARKET_PRICE", ["SimpleBank.Databases.Trading.LSEPrice.Price"], ["SimpleBank.Class Diagram.MarketData.BloombergPrice.OpeningPrice", [["SimpleBank.Class Diagram.MarketData.Bloomberg API.OpeningPrice"]]], ["SimpleBank.Class Diagram.MarketData.BloombergPrice.ClosingPrice", [["SimpleBank.Class Diagram.MarketData.Bloomberg API.ClosingPrice"]]], ["SimpleBank.Class Diagram.MarketData.BloombergPrice.SpotPrice", [["SimpleBank.Class Diagram.MarketData.Bloomberg API.SpotPrice"]]], ["SimpleBank.Class Diagram.MarketData.RuetersPrice.Bid_Price"], ["SimpleBank.Class Diagram.MarketData.RuetersPrice.Close_Price"], ["SimpleBank.Databases.Trading.LSEPrice.Price"], ["SimpleBank.Class Diagram.MarketData.RuetersPrice.Price"]]
Derivation
While the automatic derivation of data lineage from source is valuable for reporting and analysis, a derivative value includes reliable enterprise-lineage of UML flows (with referenced content) can now be properly derived.
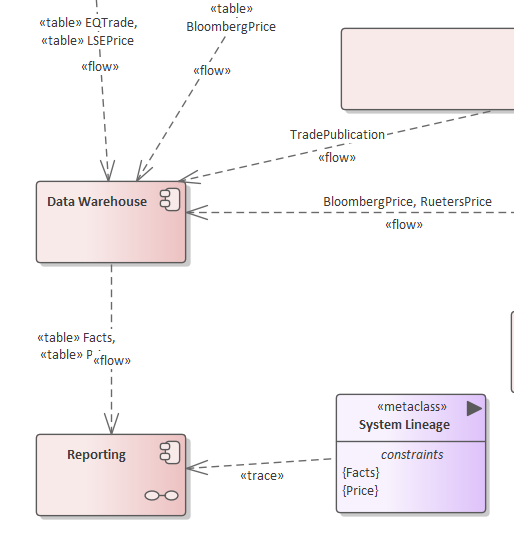
While a regulatory reporting application will commonly source Price/Trade data from a data warehouse, when the warehouse price has trace references to an LSE Equity Price and Bloomberg-Price it allows the systems lineage to be inferred from the data-flows. Enterprise Service Bus, market-data pub/sub and Event Driven Architecture can obscure the flow of data through systems because a provider will often be unaware of usage.
It will be demonstrated that system lineage can be infered from Information Flow between systems and where a tranformation is implied by data lineage
Usage
<<metadata>> summaries are most useful at the end-point where lineage needs to be demonstrated to sponsors and regulators - it can also be used at any level as a quality review for internal-lineage.
Real-time automatic derivation allows continuous improvement of domain-specific models, and overcomes the need to bridge the gap between ETL/EAI/DD tools and modern service/event orientated architectures
Conclusion
Early attempts to meet the regulatory needs of BCBS 239 have focused on using the internal lineage approaches in depth first search for lineage information.
Regulators are generally more interested in Breadth first search demonstration of product coverage and commonality of price sources; rather than the size and cost of data-governance-offices.
It is not unreasonable to conclude that failure to demonstrate lineage for BCBS 239 using internal-lineage implies that it will fail for FRTB... a better approach is available, and should be taken